%%{init: {"themeVariables": {"fontSize": "24px"}}}%%
flowchart LR
G[Goals] ==> P[Problem]
P ==> Q[Question]
Q ==> Da[Data]
Da ==> M[Model]
M ==> R[Result]
R ==> D[Decision]
style M fill:#FFD966,stroke:#333,stroke-width:3px,color:#000
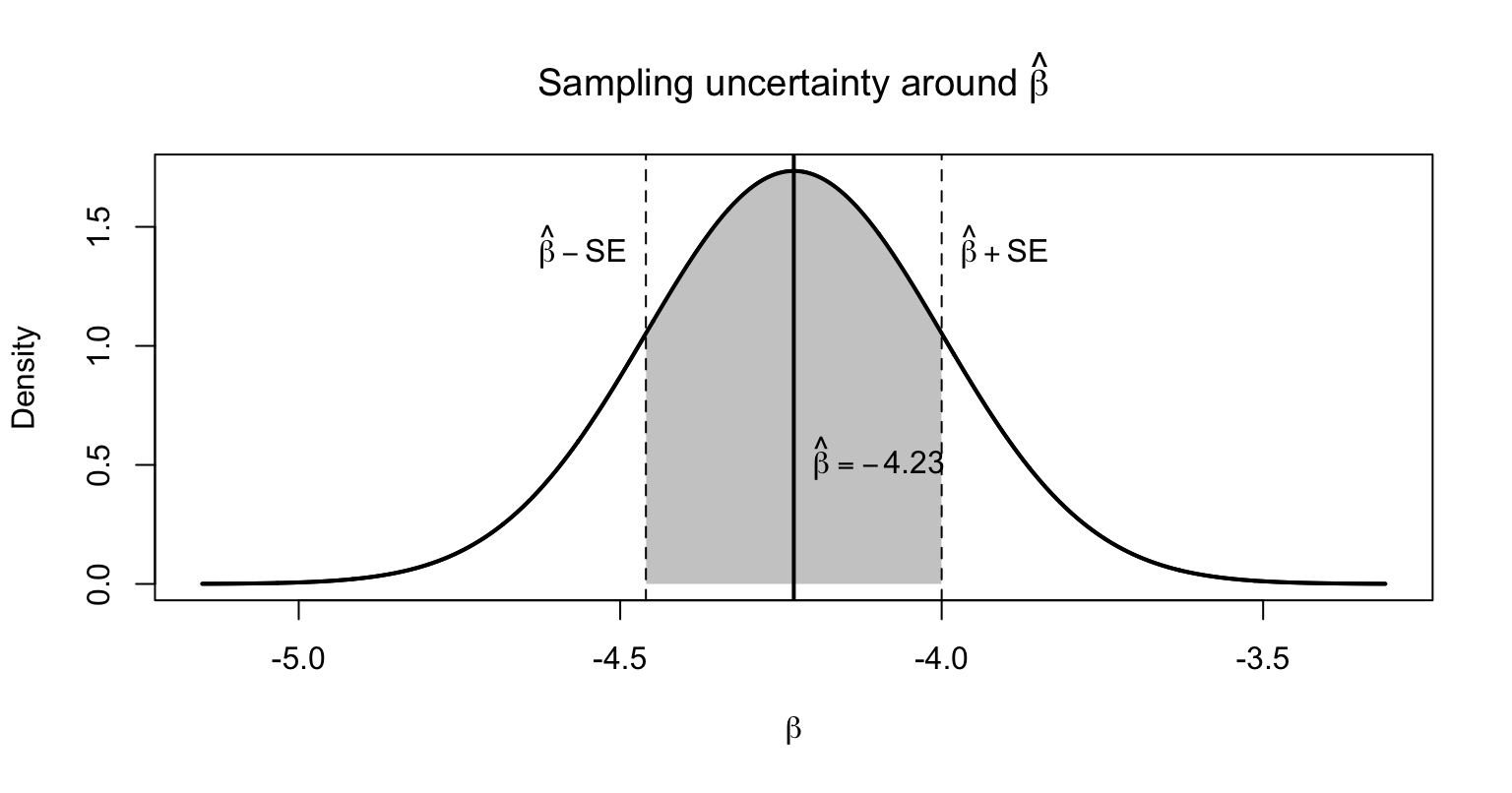
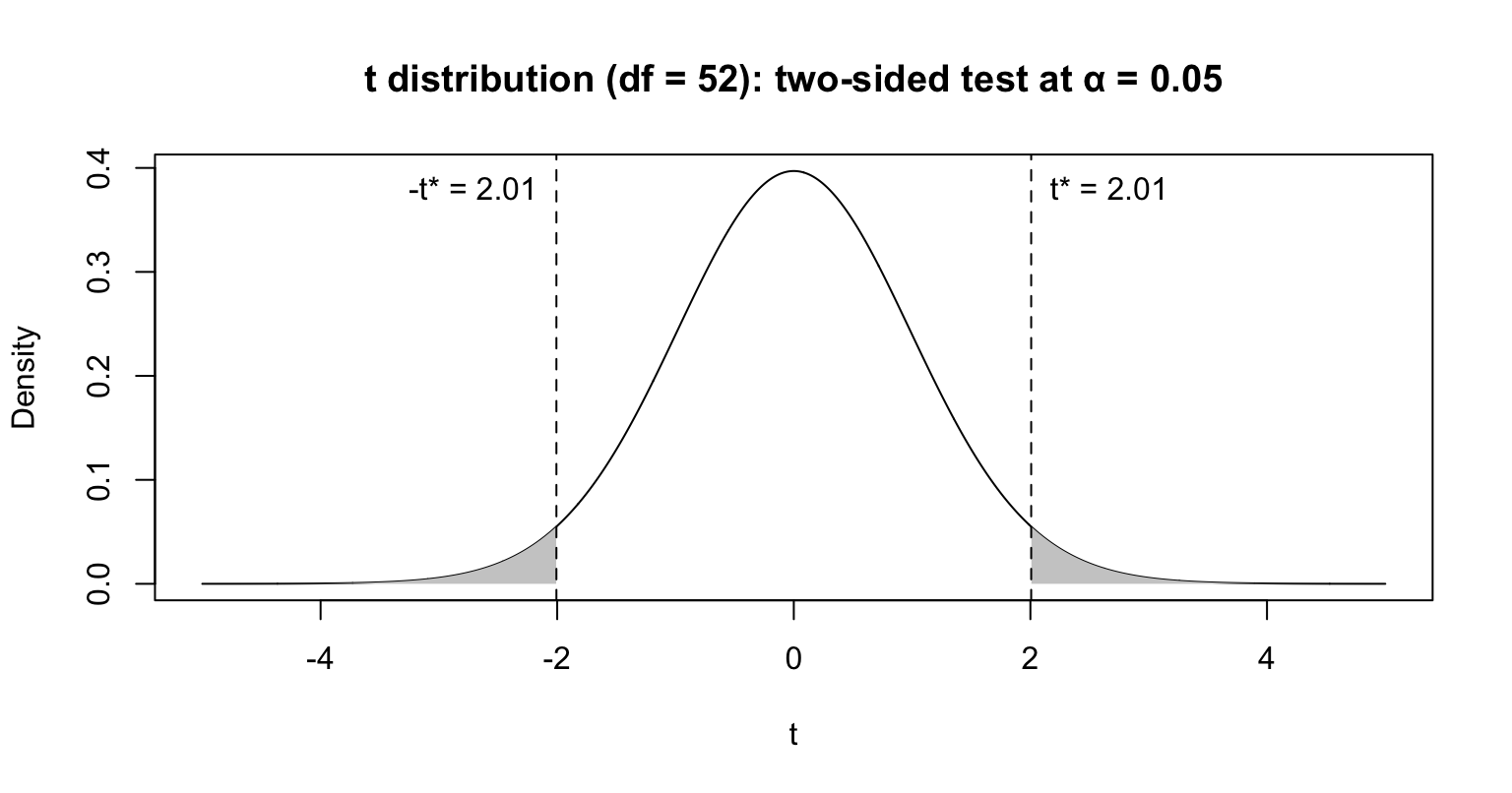
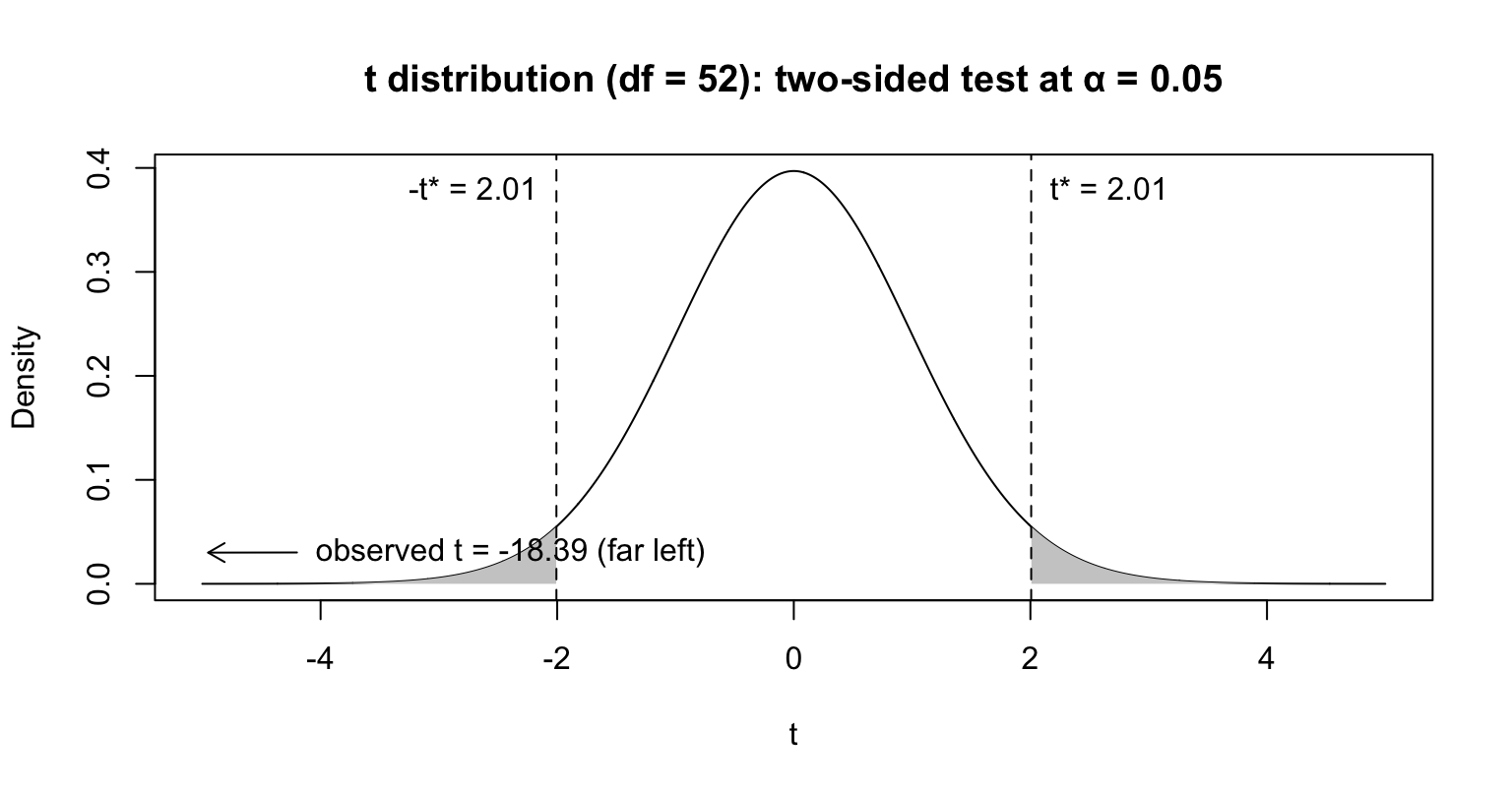
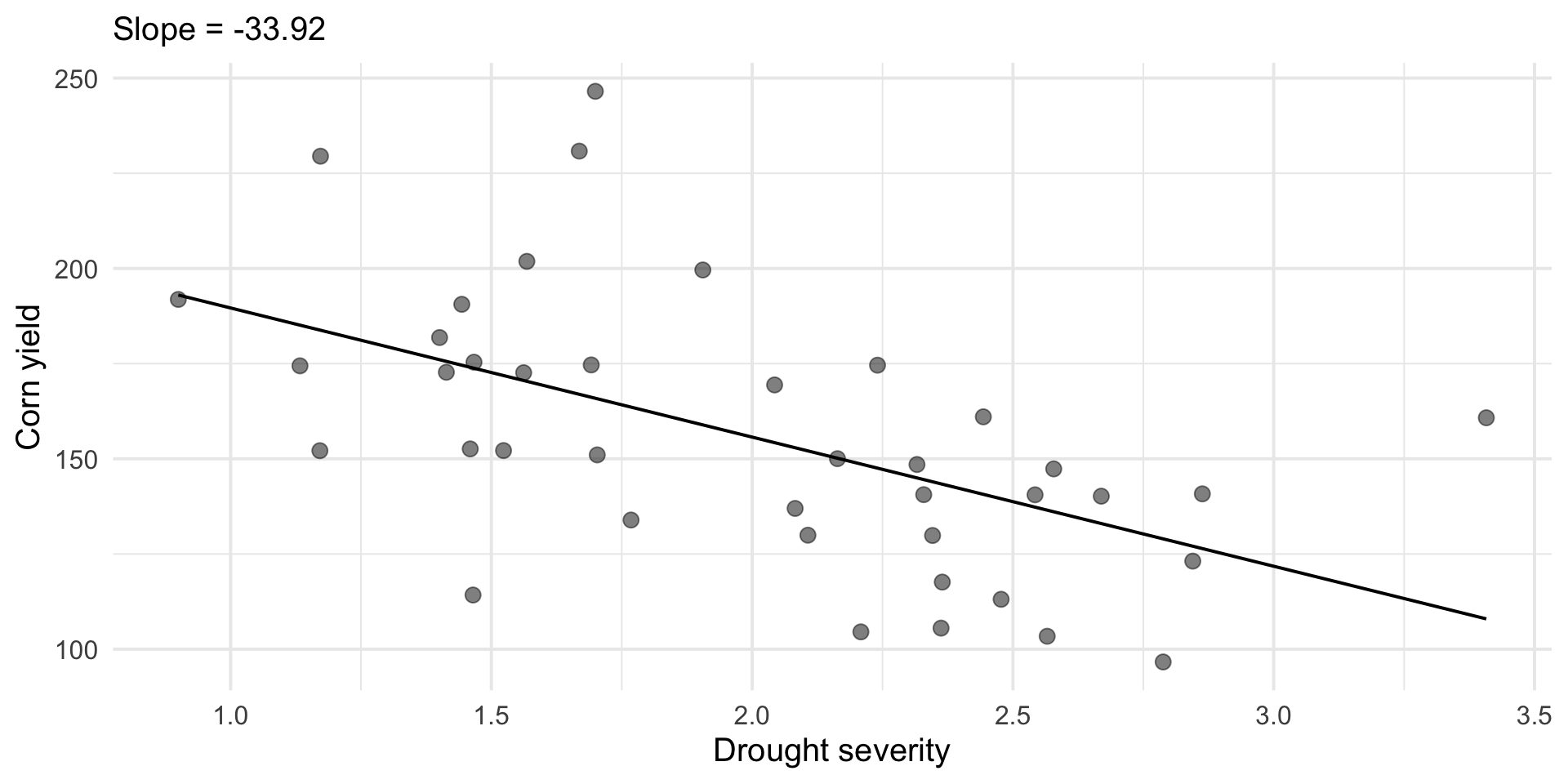
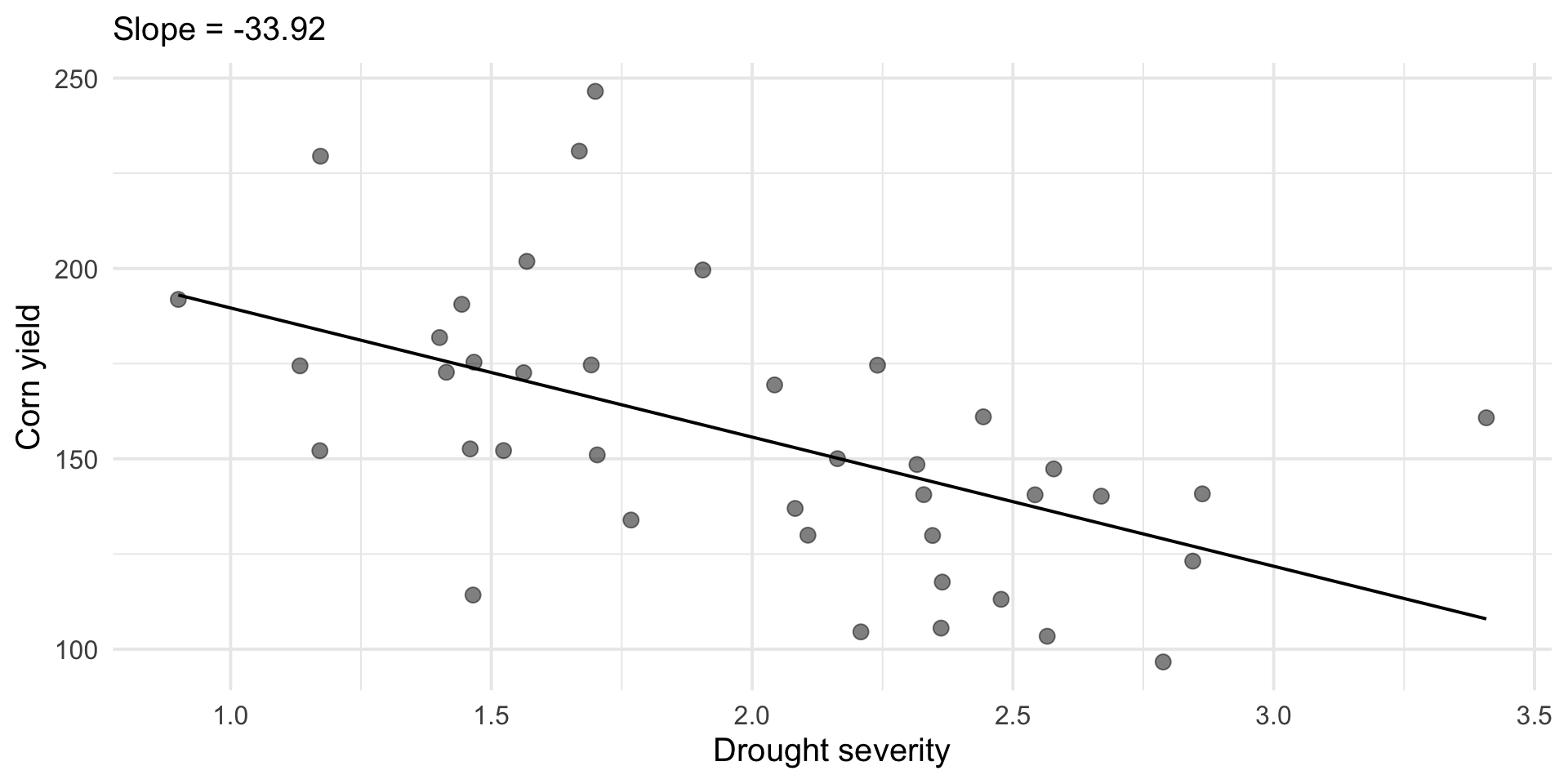
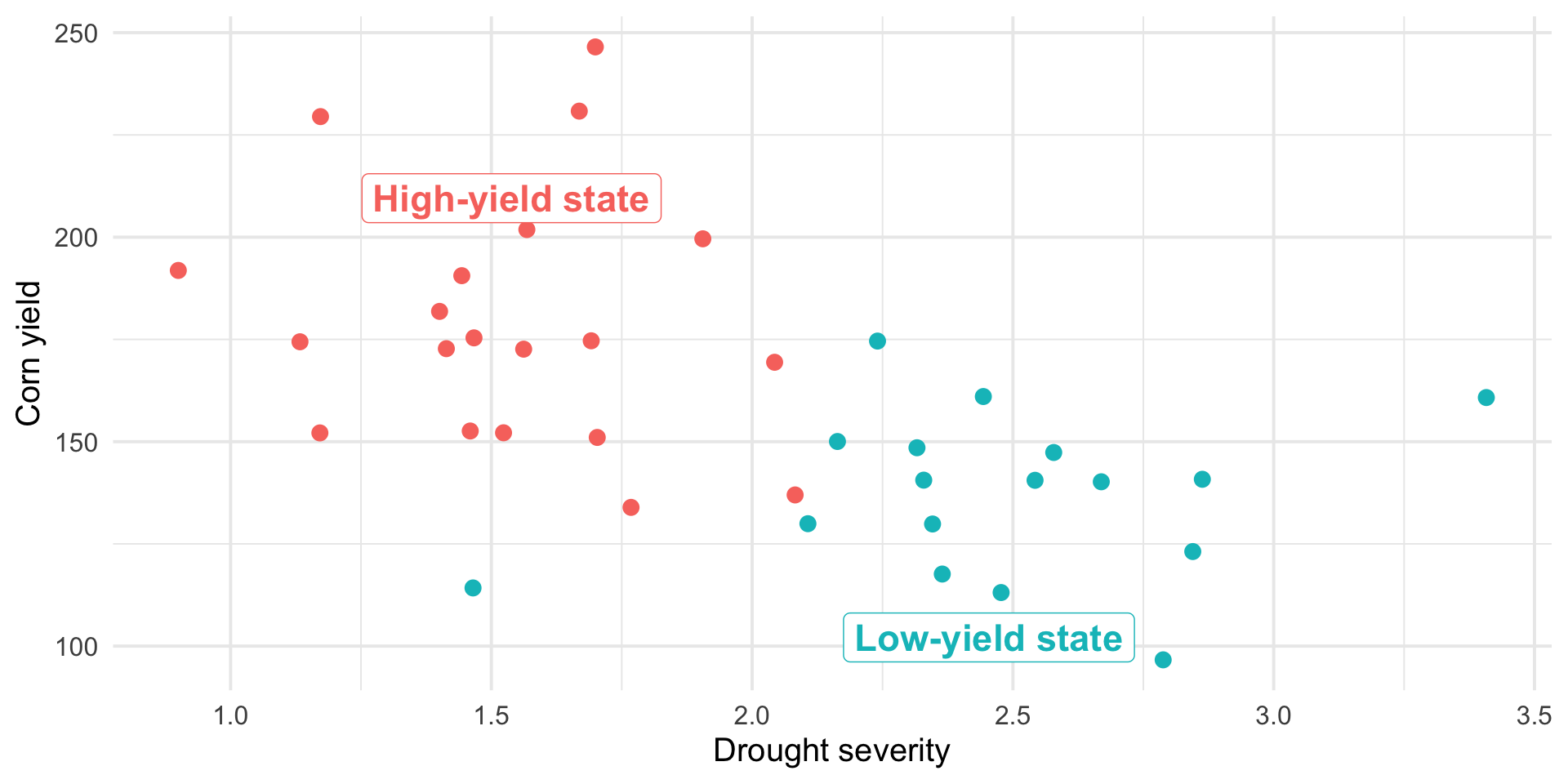
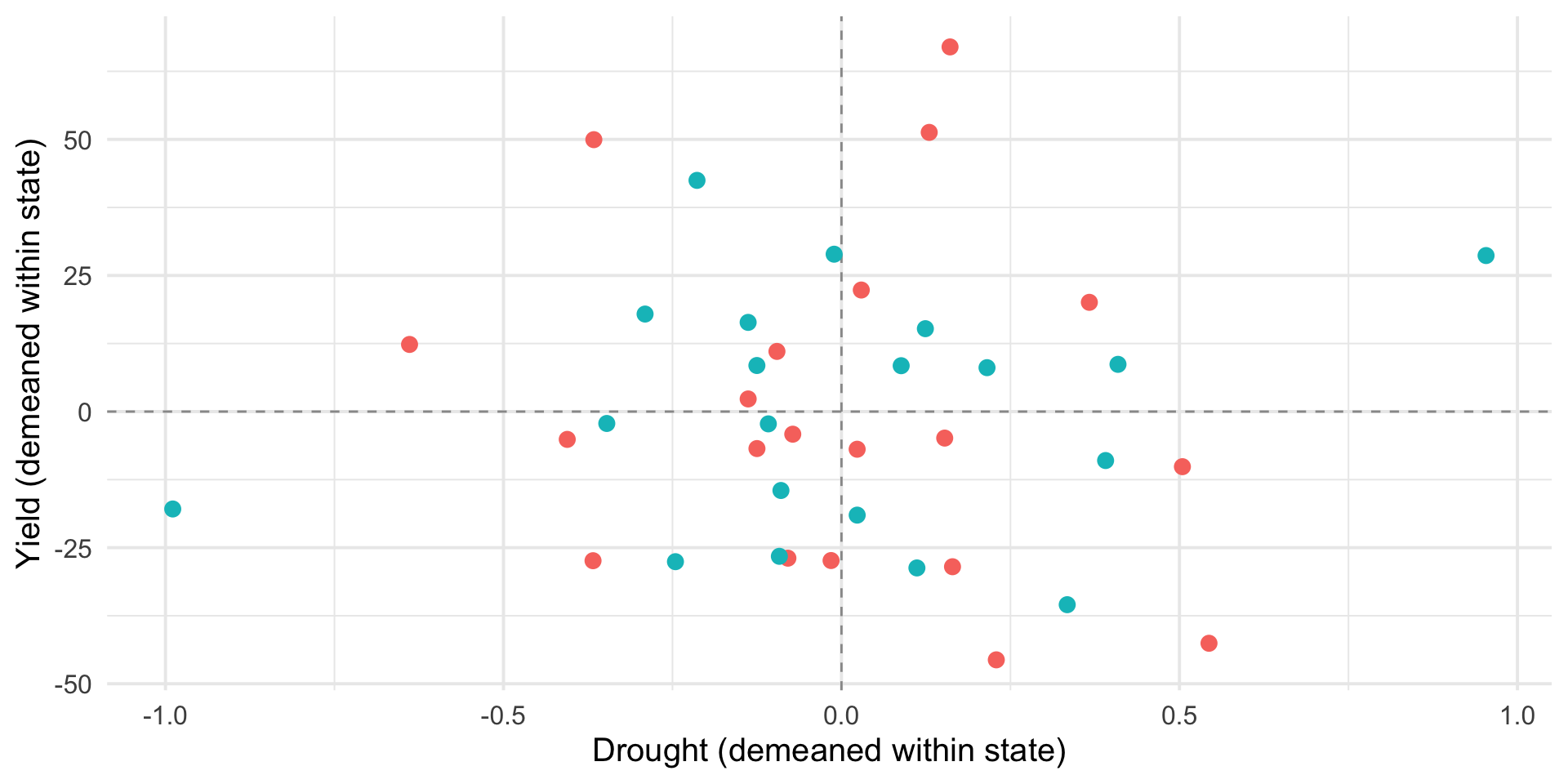
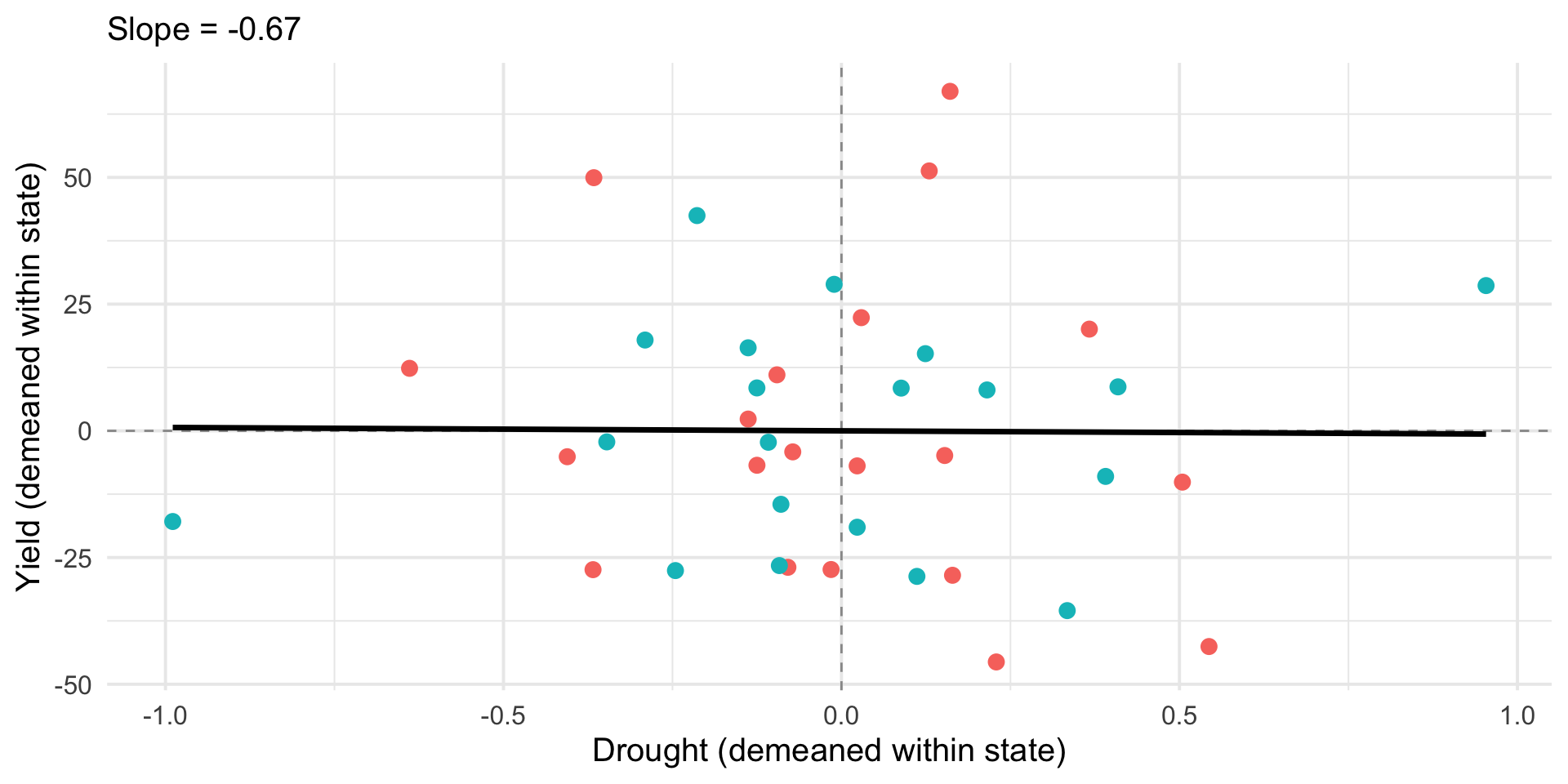
Regression is a statistical method for understanding relationships between quantitative variables